
Optimal Solution
[백준, C++] 2075 - N번째 큰 수 본문
https://www.acmicpc.net/problem/2075
2075번: N번째 큰 수
첫째 줄에 N(1 ≤ N ≤ 1,500)이 주어진다. 다음 N개의 줄에는 각 줄마다 N개의 수가 주어진다. 표에 적힌 수는 -10억보다 크거나 같고, 10억보다 작거나 같은 정수이다.
www.acmicpc.net
문제 분석
N X N 크기의 표에 수가 N^2개가 채워져 있는데, 이 표에는 특징이 있다. 바로 모든 수는 자신의 한 칸 위의 수보다 크다는 것이다. 이 표가 주어졌을 때, 이 표에서 N번째로 큰 수를 찾아야 한다(다행히 표에 채워진 수는 모두 다르다).
처음 봤을 때는 문제가 매우 쉽다고 생각했다. 그냥 N X N 배열을 만들고, 배열에 수를 입력받은 후 정렬한 다음 N번째로 큰 수를 리턴하면 되지 않나 ? 하고 생각했다(이딴 게 실버 2 ?). 그렇지만 문제를 꼼꼼히 읽어본 후 함정이 있음을 파악했다.
메모리 제한 - 12MB
N은 최대 1,500이다. 즉, 1,500 ^ 2 = 2,250,000이고, int는 4바이트니까 최대 9,000,000바이트를 사용하게 된다. 9백만 바이트를 MB로 환산해보면 9MB이다. 즉, 입력받은 수를 담는 배열과, 정렬을 하기 위한 벡터는 공존할 수가 없게 된다. 사실 이 포스트를 작성하면서 이 문제를 단순 정렬로 매우 쉽게 푸는 방법을 알긴 했는데, 문제를 접했을 때는 문제의 의도가 단순한 정렬이 아니라 머리 좀 써서 풀어라 인 것 같아서 머리를 굴려서 풀었다.
'모든 수는 자신의 한 칸 위의 수보다 크다' 라는 특성을 이용했다. 즉, 모든 열(column)은 아래에서 위로 갈수록 작아진다. 이를 좀 더 응용해 생각해보면, 마지막 행에 있는 모든 숫자들은 각각 자신이 속한 열에서 가장 큰 수라는 것이다.
| 12 | 7 | 9 | 15 | 5 |
| 13 | 8 | 11 | 19 | 6 |
| 21 | 10 | 26 | 31 | 16 |
| 48 | 14 | 28 | 35 | 25 |
| 52 | 20 | 32 | 41 | 49 |
위 표를 보자. 나는 이 문제를 어떻게 풀었냐면, rowIndices라는 배열을 두었다. rowIndices[i]는 i번째 열에서 지금 몇 번째 행을 읽어야 할 차례인지를 담는, 즉 현재 열에 대한 행의 인덱스를 담는다. rowIndices는 당연히 초기값이 다 n - 1로 세팅하고 시작한다.
그러면 초기엔 rowIndices에는 전부 4 가 들어있을 것이다(n == 5). 그럼 여기서 내가 할 일은, rowIndices를 한 번씩 돌면서 각 열에서 지금 읽어야 할 행 정보를 얻어온다. 즉, i가 0부터 n - 1까지 증가하면서, arr[rowIndices[i]][i]가 우리가 읽어야 할 값이라는 것이다. 그리고 이 중에서 최대값을 얻어온다. 그리고 읽어온 열에 대해서 rowIndices[i]를 1 감소시킨다. 이 짓을 n번만 반복하면 N번째 큰 수를 찾을 수 있다. 아마 문제가 의도한 바는 이것이라고 생각했다(단순히 정렬해서 푸는 게 아닌).
이 방법으로 위의 문제를 풀어보면,
1번째로 큰 수 구하기)
rowIndices = {4, 4, 4, 4, 4}
읽어온 값 = 52, 20, 32, 41, 49
최대값 = 52
rowIndices 갱신 -> rowIndices = {3, 4, 4, 4, 4}
2번째로 큰 수 구하기)
rowIndices = {3, 4, 4, 4, 4}
읽어온 값 = 48, 20, 32, 41, 49
최대값 = 49
rowIndices 갱신 -> rowIndices = {3, 4, 4, 4, 3}
...
5번째로 큰 수 구하기)
rowIndices = {2, 4, 4, 3, 3}
읽어온 값 = 21, 20, 32, 35, 25
최대값 = 35
rowIndices 갱신 -> rowIndices = . . . (사실 이제 필요없다)
이걸 코드로 구현했다.
코드
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int n;
int arr[1500][1500];
int rowIndices[1500];
int result;
struct NumberInfo {
int value;
int columnIndex;
NumberInfo(int value, int columnIndex) {
this->value = value;
this->columnIndex = columnIndex;
}
};
bool compare(NumberInfo ni1, NumberInfo ni2) {
return ni1.value > ni2.value;
}
int getMaxValue() {
vector<NumberInfo> vec;
for (int j = 0; j < n; j++) {
int index = rowIndices[j];
vec.push_back(NumberInfo(arr[index][j], j));
}
sort(vec.begin(), vec.end(), compare);
NumberInfo greatestNumberInfo = vec[0];
rowIndices[greatestNumberInfo.columnIndex]--;
return greatestNumberInfo.value;
}
void getInput() {
cin >> n;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
cin >> arr[i][j];
}
}
}
void solve() {
int count = 0;
for (int i = 0; i < n; i++) {
rowIndices[i] = n - 1;
}
int lastMaxValue = 1e9 + 1;
for (int i = 0; i < n; i++) {
lastMaxValue = getMaxValue();
}
result = lastMaxValue;
}
void printResult() {
cout << result << "\n";
}
int main() {
cin.tie(NULL);
ios::sync_with_stdio(false);
getInput();
solve();
printResult();
return 0;
}
코드 설명
전체적인 풀이는 위에서 글로 설명한 바와 같다. 하지만 이 코드에는 불필요한 부분이 몇 가지 있다.
1. 사실 lastMaxValue 변수는 필요 없다. 이전의 최대값을 쓸 일은 없기 때문이다. 근데 나는 그냥 가독성을 목적으로 반복문 안에 result = getMaxValue(); 대신에 lastMaxValue라고 썼는데, 이게 가독성을 더 해칠 수도 있을 것 같단 생각이 방금 들었다.
2. 굳이 sort 메서드를 사용할 필요 역시 사실 없다. 단순히 반복문을 돌려서, 최대값과 최대값이 있는 열의 인덱스를 가져와도 된다. 근데 이걸 쓴 이유는 내가 sort 메서드를 쓸 때 자꾸 compare 메서드를 어떻게 만들어야 하는지 깜빡하면서 구글링하고, '아 맞다' 했기 때문에 익숙해지려고 일부러 구조체도 만들고 compare 메서드도 만들고 그랬다.
3. 2번과 같은 이유로 구조체 역시 필요가 없긴 하다.
로직 자체가 생각하기 어려운 것은 아니라 생각한다. 아마 이 문제는 이런 로직으로 푸는 게 문제 의도에 맞았을 것이라 생각한다. 그런데 뭔가 찝찝하다.
찝찝한 것
메모리 제한이 12MB였다. 그리고 N이 최대 1,500이니까, 입력으로 들어올 숫자는 최대 225만 개이다. 그리고 int는 4바이트니까, 표의 숫자를 저장하기 위해 필요한 메모리는 900만 바이트, 즉 9MB이다.
2차원 배열을 안 쓰고 벡터에 바로 입력받으면 메모리 초과 안 날 것 같은데 ?
그러면 애초에 2차원 배열에 입력을 받고, 그걸 벡터로 옮기는 게 아니라 처음부터 벡터에 입력받으면 되는 게 아닐까 ? 그럼 당연히 메모리 초과를 피할 수 있을텐데 말이다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int n;
vector<int> vec;
int result;
int main() {
cin.tie(NULL);
ios::sync_with_stdio(false);
cin >> n;
for (int i = 0; i < n * n; i++) {
int value;
cin >> value;
vec.push_back(value);
}
sort(vec.begin(), vec.end());
result = vec[vec.size() - n];
cout << result << "\n";
}
하지만 제출해보니 메모리 초과가 났다. 왜일까 ?
C++의 벡터는 동적 배열로 구성되는데, 배열이 가득 차면 기존 크기의 1.5배의 새로운 동적 배열을 생성해 원소를 옮기게 된다. 즉, 새로운 원소를 삽입할 때 동적 배열이 가득 찼다면 크기를 1씩 증가시키는 게 아니라 1.5배씩 증가시키면서 어느 정도 여유 공간을 가진다는 뜻이다. 실제로 벡터에 225만 개의 원소를 삽입한 후, vec.size()가 아닌 vec.capacity()를 출력해보면
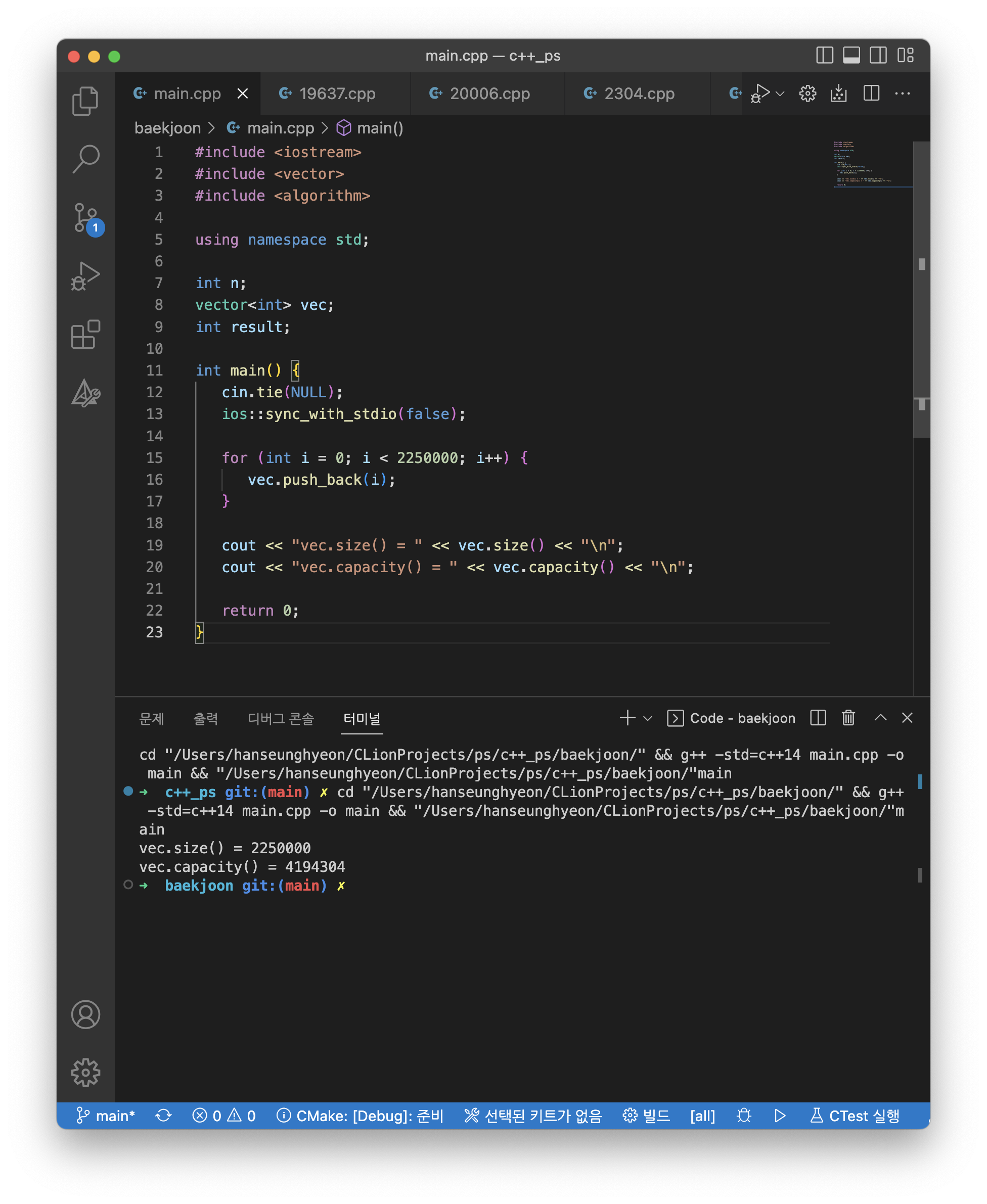
size는 225만이지만, capacity는 400만을 넘어서는 것을 확인할 수 있다. 즉, int형은 4바이트이므로 벡터는 1600만 바이트, 즉 16MB 이상을 사용하게 되기 때문에 메모리 초과가 발생할 수 있다는 것이다.
벡터가 문제면 배열 쓰면 되겠네 ?
벡터를 사용했을 때 왜 문제가 되는지는 알았다. 그럼, 크기가 225만인 배열을 만들어놓고 쓰면 되지 않을까 ? 아래 코드처럼 말이다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int n;
int result;
int main() {
cin.tie(NULL);
ios::sync_with_stdio(false);
int arr[2500000];
cin >> n;
for (int i = 0; i < n * n; i++) {
cin >> arr[i];
}
sort(arr, arr + n * n);
result = arr[n * n - n];
cout << result << "\n";
return 0;
}
유감스럽지만 이 코드는 실행이 안 된다.
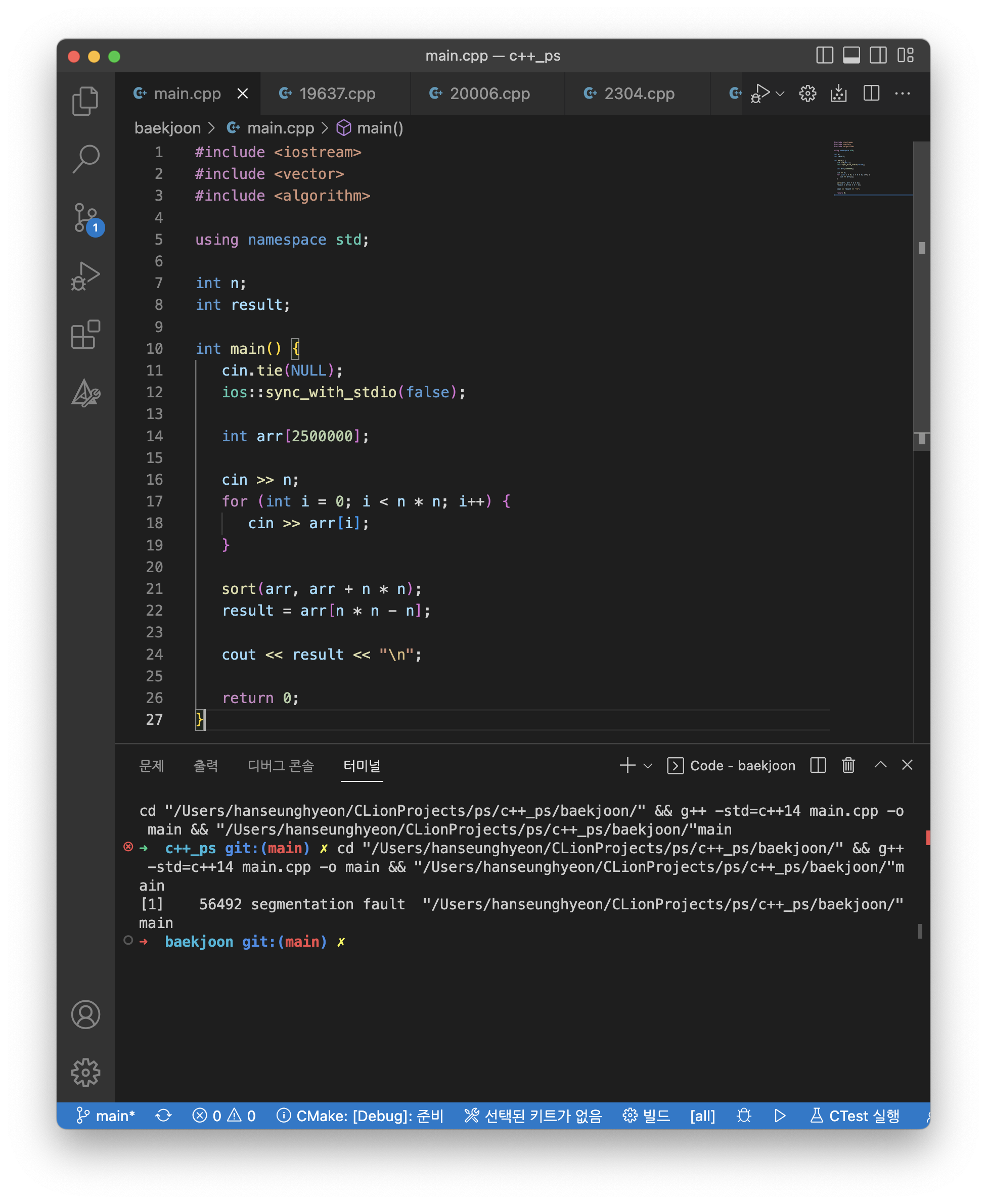
왜 날 억까할까. 250만 개를 저장하는 벡터는 잘만 실행시켜 주면서 말이다.
16번 라인부터 26번 라인까지 주석 처리를 하고 다시 실행시켜도 여전히 segmentation fault로 뜨는 것을 보아, 배열을 선언하는 코드 자체에서 문제가 발생했다고 여겨진다. 그래서 조금 더 찾아보니, 지역 변수의 크기가 너무 크면 Stack Overflow가 발생할 수 있고 이로 인해 segmentation fault가 발생할 수 있다고 한다.
결국 찾아낸 절충안
결론부터 말하자면,
1. 벡터를 사용해서 풀고자 한다면 벡터 선언 시 크기를 지정해준다(배열 쓰듯이)
2. 전역 변수에 선언한다.
이 2가지를 통해 위에서 설명한 문제 풀이 로직 없이 단순 정렬만으로 풀 수 있다.
1. 벡터 사용 시 크기 지정 및 전역 변수로 선언
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int n;
vector<int> vec(2500000);
int result;
int main() {
cin.tie(NULL);
ios::sync_with_stdio(false);
cin >> n;
for (int i = 0; i < n * n; i++) {
cin >> vec[i];
}
sort(vec.begin(), vec.begin() + n * n);
result = vec[n * n - n];
cout << result << "\n";
return 0;
}
2. 배열 사용 시 전역 변수로 배열 선언
#include <iostream>
#include <algorithm>
using namespace std;
int n;
int arr[2500000];
int result;
int main() {
cin.tie(NULL);
ios::sync_with_stdio(false);
cin >> n;
for (int i = 0; i < n * n; i++) {
cin >> arr[i];
}
sort(arr, arr + n * n);
result = arr[n * n - n];
cout << result << "\n";
return 0;
}
두 코드 모두 시원하게 정답입니다 ! 를 뱉어낸다.
마무리하며
사실 '마무리하며' 따위의 제목을 쓴 적이 없었는데(블로그 써봐야 얼마나 썼다고 ... ㅋㅋ), 이 문제는 뭔가 혼자 생각하다보니 '아니 더 쉽게 될 것 같은데' 라고 생각하며 될 것 같은 그 근거를 고민해보고 새로 코드를 짰고, 그런데도 메모리 초과 및 실행 오류를 마주하게 되면서 '아니 분명 내 머리로는 되는데 왜 안 되지 ?' 하면서 이론적인 내용을 좀 더 학습했다. 그리고 이런 소득을 얻었다.
1. 내가 사용하는 자료구조의 동작 원리를 명확히 이해할 것(벡터가 차지하는 메모리 크기가 size * sizeof(자료형) 일 것이라 혼자 지레짐작했음)
2. 지역 변수로 크기가 큰 변수를 할당하게 될 경우 프로그램의 동작과 관계없이 segmentation fault가 발생할 수 있다는 것(지금껏 사실 segmentation fault는 실행을 돌리면서 입력을 넣어주다가 마주한 경우가 많아 변수 할당이 아닌 이상한 주소를 참조하고 있을 때만 일어난다고 생각했음)
사실 이 문제 자체는 정말 별 거 아닌 문제였다. 그런데 생각보다 이 문제를 풀면서, 더 쉽게 풀어보려고 시도하면서 많은 것을 배울 수 있었다. 그래서 기분이 좋다. 이따 저녁 먹을건데 아주 후련하게 먹을 듯.
'알고리즘' 카테고리의 다른 글
| [백준, C++] 14940 - 쉬운 최단거리 (0) | 2023.09.04 |
|---|---|
| [백준, C++] 1138 - 한 줄로 서기 (0) | 2023.09.04 |
| [백준, C++] 11501 - 주식 (0) | 2023.09.01 |
| [백준, C++] 2304 - 창고 다각형 (0) | 2023.09.01 |
| [백준, C++] 20006 - 랭킹전 대기열 (0) | 2023.08.31 |
